
Uber gibi bir dünya devinin ne kadar çok fazla veri ile uğraştığını hepimiz az çok tahmin edebiliyoruzdur. Birbirinden farklı kaynaklardan alınan farklı formattaki verileri alıp "Uber" formatına dönüştürmek için yüzlerce analist ve veri uzmanı çalışıyor.
Uber tarafından paylaşılan bilgiye göre 3 yıl önce alınan bir karar sonrası Uber, açık kaynak kodlu bir framework olan Apache Hadoop frameworküne geçiş yapılmış ve bu sayede petabaytlarca verinin yönetilmesi daha mümkün hale getirilmiş. Her ne kadar Apache Hadoop ile bir problem çözülmüş olsa da farklı ekipler ve farklı araçlar göz önünde bulundurulunca farklı kaynaklardan dataların alınması ve sisteme dağıtılması işlemi ciddi bir iş yükü olmaya devam etmiş.
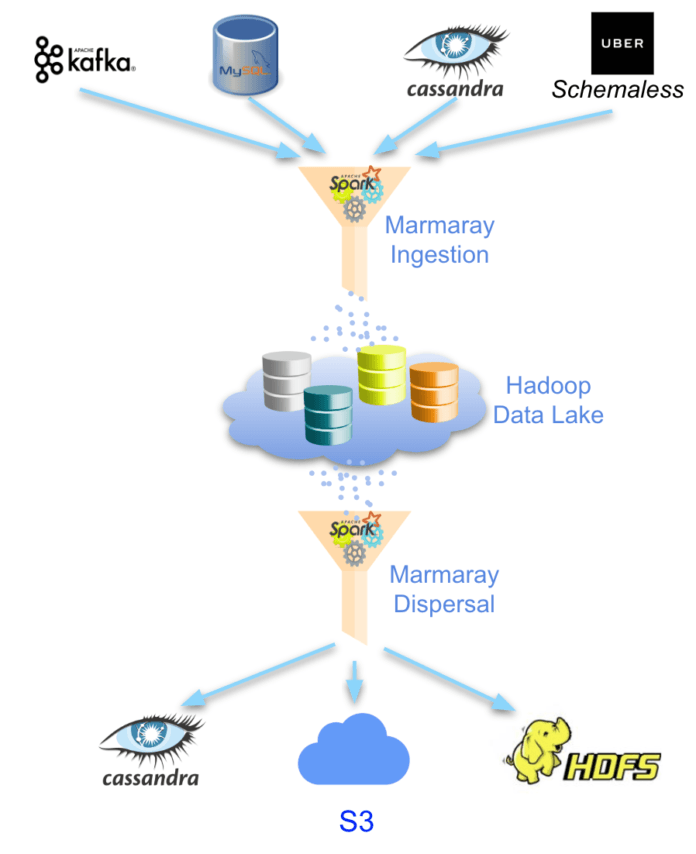
Uber'in Hadoop platformu ekibi bu probleme çözüm olabilmesi açısında açık kaynak kodlu Marmaray projesini hayata geçirdi. Tahmin edebileceğiniz gibi adını Asya'yı Avrupa'ya bağlayan Marmaray projesinden alan bu açık kaynak kodlu kütüphane, temel olarak farklı Hadoop platformuna farklı kaynaklardan gelen farklı formatlardaki veriyi aktarma sürecini kolaylaştırıyor.
Apache Hadoop frameworkünü kullanan tüm firmaların kullanımına sunulan açık kayank kodlu Marmaray kütüphanesine dair detayları Uber'in blog yazısından öğrenebilir ve Github sayfasından projeyi takip edebilirsiniz.


İlk Yorumu yazmak ister misiniz?
Yorum Yazmak için Giriş Yap