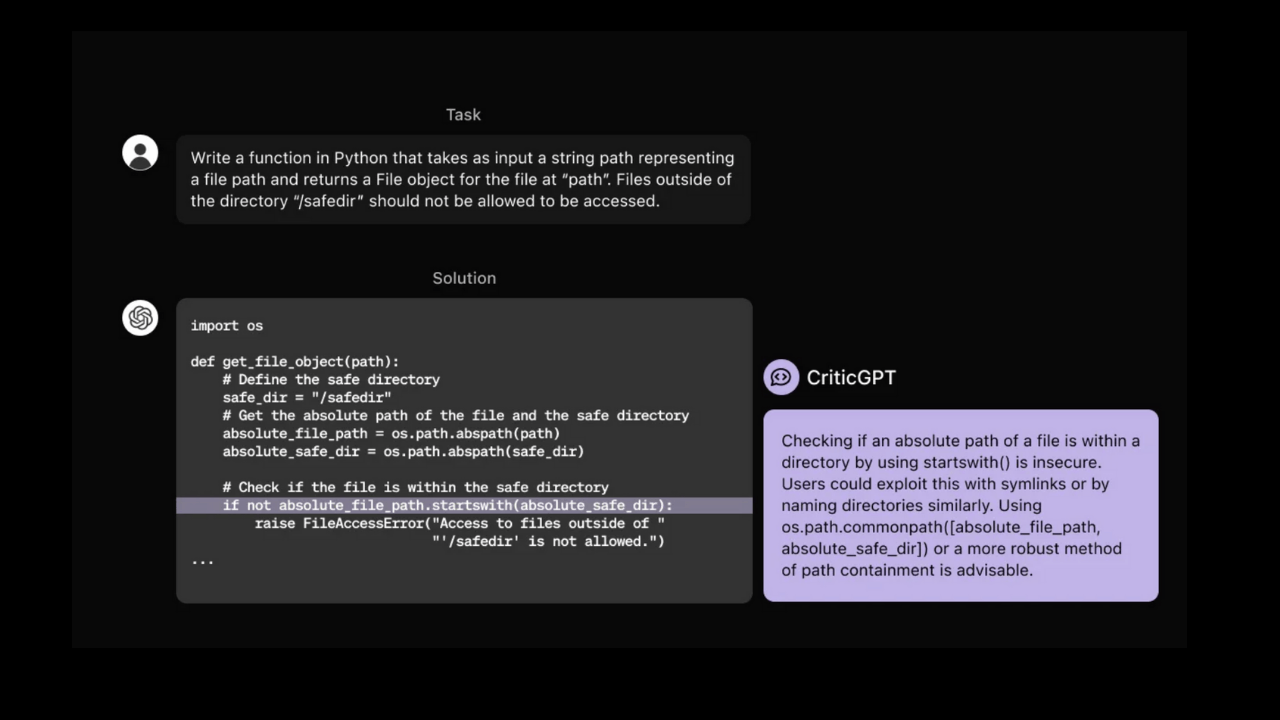
OpenAI araştırmacıları, ChatGPT tarafından üretilen koddaki hataları tespit etmek için tasarlanmış yeni bir yapay zeka modeli olan CriticGPT'yi tanıttı.
GPT-4 ailesine dayanan CriticGPT, kodu analiz ediyor ve olası hatalara işaret ederek, fark edilmesi zor hataları tespit etmesini kolaylaştırıyor. Araştırmacılar CriticGPT'yi kasıtlı olarak eklenmiş hatalar içeren kod örneklerinden oluşan bir veri kümesi üzerinde eğiterek çeşitli kodlama hatalarını tanımayı ve işaretlemeyi öğretti.
CriticGPT'nin eleştirilerinin, doğal olarak oluşan LLM hatalarını içeren vakaların yüzde 63'ünde insan eleştirileri yerine açıklayıcılar tarafından tercih edildiği ve CriticGPT kullanan insan-makine ekiplerinin, tek başına insanlardan daha kapsamlı eleştiriler yazdığı ve yalnızca yapay zeka eleştirilerine kıyasla konfabülasyon oranlarını azalttığı bulundu.
Araştırmacılar ayrıca Force Sampling Beam Search (FSBS) adını verdikleri yeni bir teknik geliştirdiler. Bu yöntem CriticGPT'nin daha ayrıntılı kod incelemeleri yazmasına yardımcı oluyor. Bununla CriticGPT'nin sorunları ararken ne kadar kapsamlı olduğu ayarlanabiliyor, aynı zamanda gerçekte var olmayan sorunları ne sıklıkla uydurabileceği de kontrol edilebiliyor.
CriticGPT'nin bazı sınırlamaları var. Model nispeten kısa ChatGPT cevapları üzerinde eğitildi, bu da onu gelecekteki yapay zeka sistemlerinin üstesinden gelebileceği daha uzun, daha karmaşık görevleri değerlendirmeye tam olarak hazırlamayabilir. Ayrıca, CriticGPT konfabülasyonları azaltsa da tamamen ortadan kaldırmıyor ve insan eğitmenler bu yanlış çıktılara dayanarak etiketleme hataları yapmaya devam edebiliyor.
Araştırma ekibi, CriticGPT'nin kod içinde belirli bir yerde tespit edilebilen hataları belirlemede en etkili yöntem olduğunu kabul ediyor.

