
Google, Carnegie Mellon ve Cornell Üniversiteleri işbirliği ile, yüksek kaliteli görsel veritabanı The Open Images’ı yayınladı. 6000 kategoriye ayrılmış 9 milyona yakın veri, ilk önce bilgisayarlar tarafından etiketlendi. Bu etiketler, daha sonrasında insanların onayına sunuldu ve yanlış olanlar düzeltildi. Görsel başına ortalama 8 etiketin bulunduğu dataset, Google araştırma ekibine göre bir sinir ağını sıfırdan eğitebilecek kadar çok veriye sahip.

Geçtiğimiz yıllarda, bilgisayarların fotoğraf ve videolardan anlam çıkarabilmesi adına önemli gelişmeler oldu. İnsan görsel sisteminin yapabileceklerini (veriyi yakalamak, işlemek ve analiz etmek) makinelere devretme amacı taşıyan Computer Vision, makine öğrenmesi kullanarak görüntülere anlam kazandırdı.
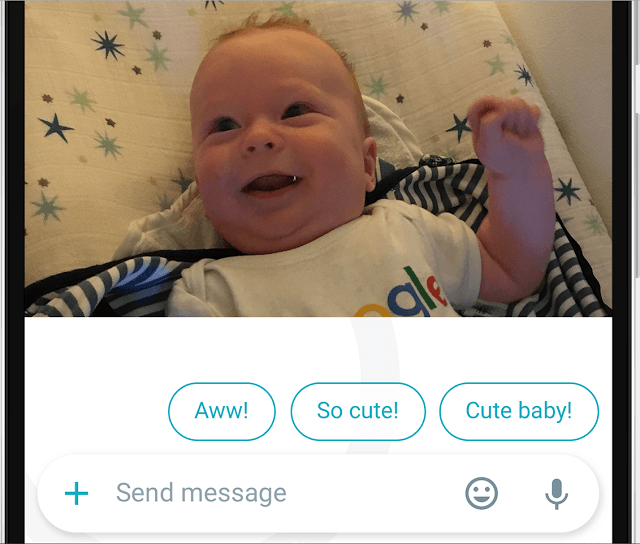
Google imzasını taşıyan mesajlaşma uygulaması Allo da aynı prensipten yararlanmıştı. Bir bebek fotoğrafını tanıyarak ona 'çok tatlı, tatlı bebek' gibi yorum önerileri sunan uygulama, makine öğrenmesi sayesinde bunu yapabiliyordu. Daha önceden sunulan sayısız bebek fotoğrafı sayesinde adeta dersine çalışıp gelen Allo, bir bebek fotoğrafını diğerlerinden ayırt edebilir hale geliyor.
Makine öğrenimi alanında daha fazla gelişme kaydedebilmek için çok fazla verinin makinelere ‘çalıştırılması' lazım. Google’ın paylaştığı The Open Images, işte bu sebepten ötürü büyük önem taşıyor. Fotoğrafların dışında videolar da, objeleri tanıma, insan davranışlarını ve insanların dünya ile etkileşimini anlama adına önemli. Google geçtiğimiz günlerde, 8 milyon etiketlenmiş videoyu Youtube-8m adı altında toplayarak yayınlamıştı. Bu büyüklükte bir video dataset, Big Data’ya (Büyük Veri) erişme imkanı olmayan araştırmacıların, geniş ölçekte çalışmalar yürütebilmesine yardımcı olabilir.


İlk Yorumu yazmak ister misiniz?
Yorum Yazmak için Giriş Yap