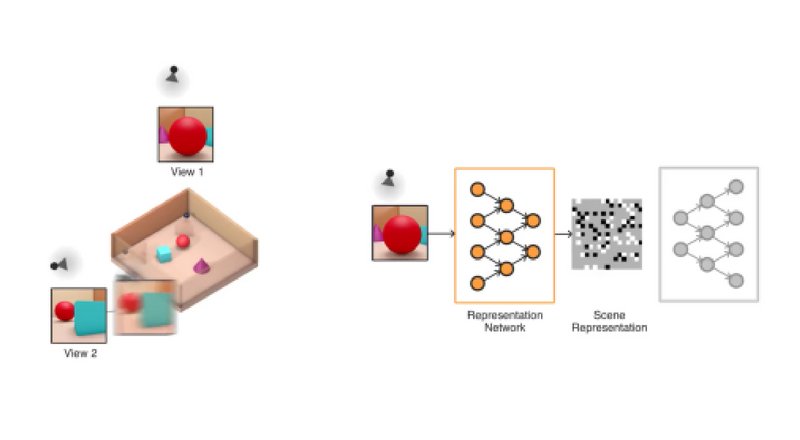
DeepMind, iki boyutlu görselleri üç boyutlu nesnelere dönüştüren artırılmış gerçeklik algoritması olan Generative Query Network'ü (GQN) tanıttı.
İnsan beyninin çevresini ve nesneler arasındaki fiziksel etkileşimleri öğrenmesini, yapay zeka araştırmacılarının dataset'lerdeki görüntülere açıklama eklenmesi ihtiyacını ortadan kaldırmayı amaçlayan Generative Query Network, "imagine" butonu ile bir insan gözetimi ya da eğitim olmadan herhangi bir açıdan 3D sahneleri oluşturabiliyor.
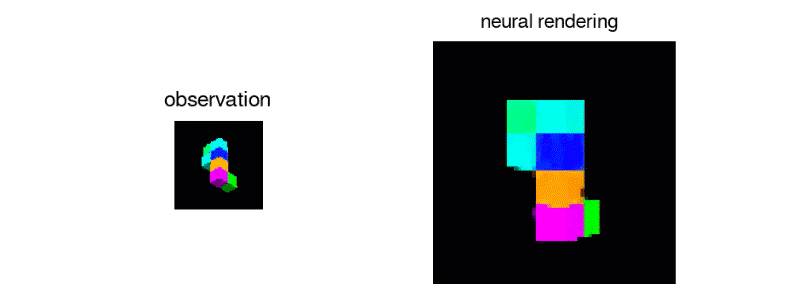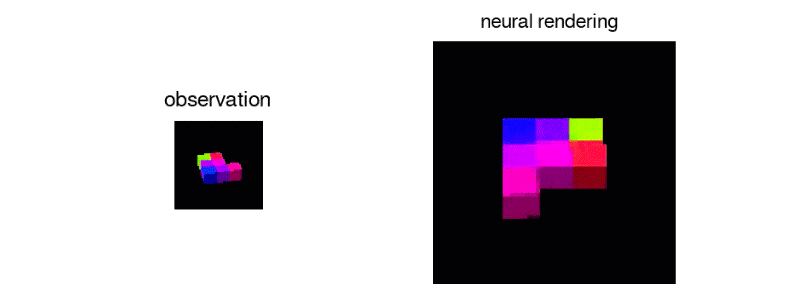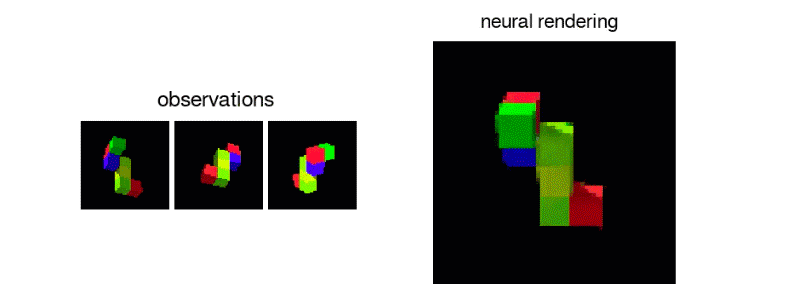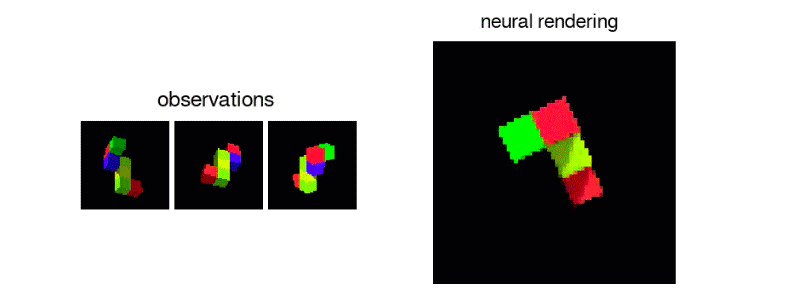
Generative Query Network algortiması, nesnelerin karşıt, görünmeyen yanlarını oluşturabilir ve aydınlatma gibi etkenleri bile hesaba katarak, birden fazla noktadan 3D görünüm oluşturabilir. Çoğu görsel tanıma sistemi, her nesnenin bütün yönlerini bir veri kümesinde, zahmetli ve maliyetli bir süreçte etiketlemesini gerektirir. Generative Query Network ise bunu en basite indirgemeyi amaçlıyor.
DeepMind araştırmacıları bir blog yazısında şu açıklamaları yaptı: "Bebekler ve hayvanlar gibi, GQN etrafındaki dünya gözlemlerini anlamayı deneyerek öğreniyor. Bunu yaparken, GQN sahnelerin içeriğini etiketlemeksizin, makul sahneleri ve geometrik özelliklerini öğrenir."
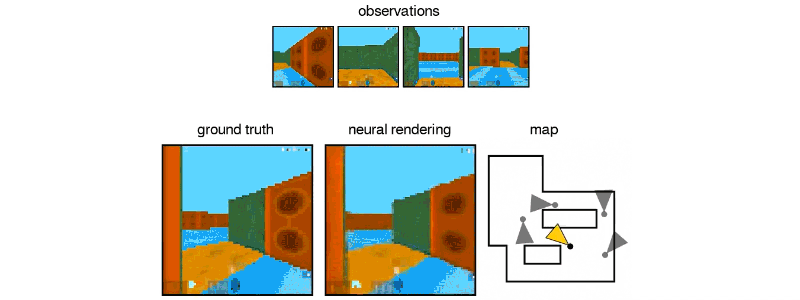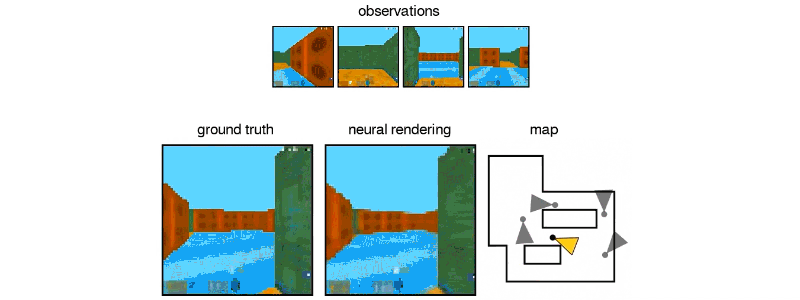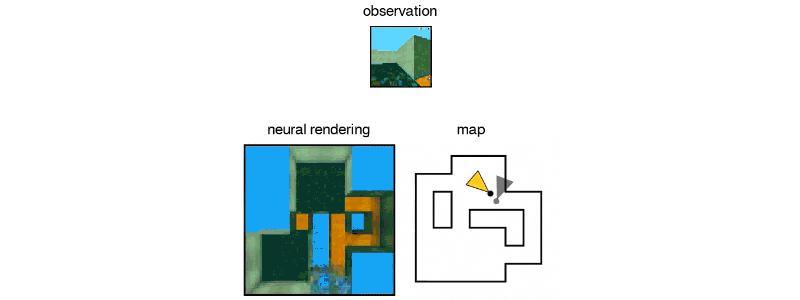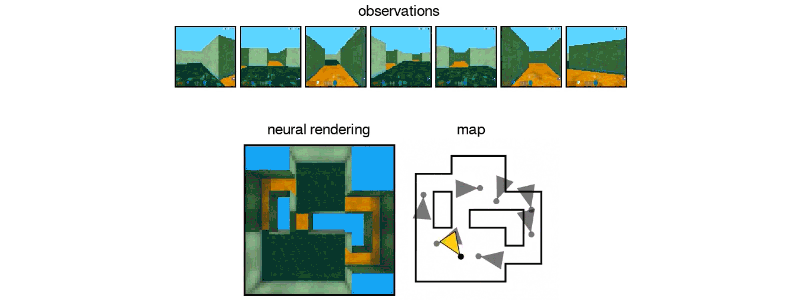
İki parçalı sistem bir temsil ağından ve bir üretim ağından oluşuyor. İlk giriş verilerini alıyor ve sahneyi tanımlayan bir matematiksel temsile (vektöre) dönüştürüyor ve bu görüntüler de sahneyi görüntülüyor. Sistemi eğitmek için, DeepMind araştırmacıları, farklı açılardan sahnelerin GQN görüntülerini besliyorlar ve bu da nesnelerin birbirinden bağımsız olarak dokuların, renklerin ve ışıkların ve bunların arasındaki mekansal ilişkilerin öğretilmesini kapsıyor. Daha sonra bu nesnelerin yan yana ya da arka arkaya nasıl görüneceğini tahmin ediyorlar.
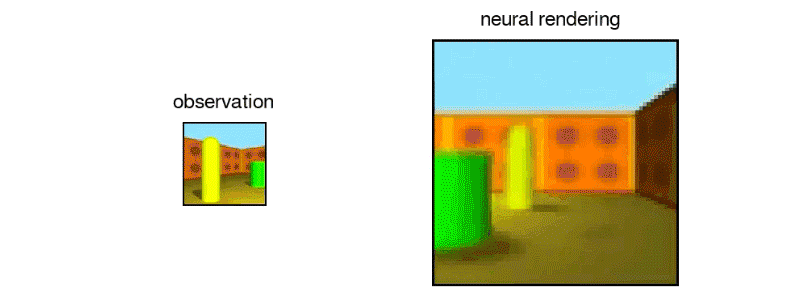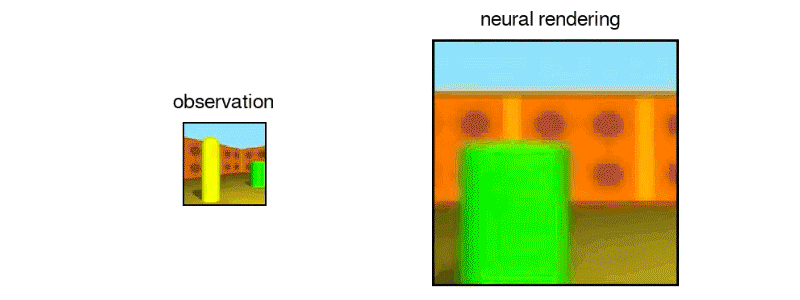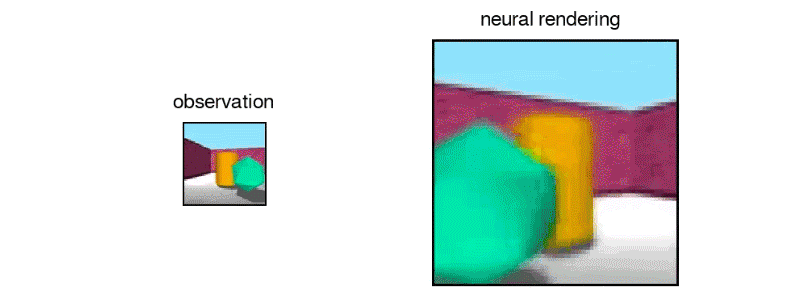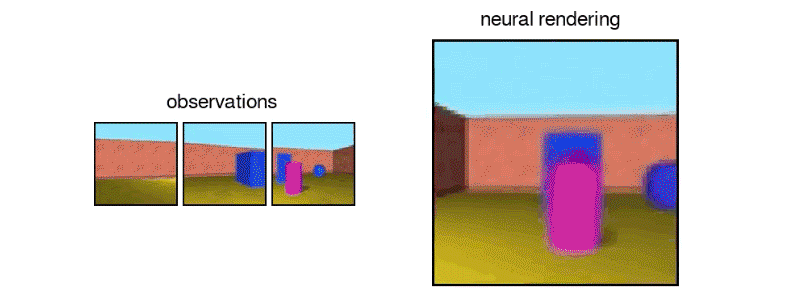
Mekansal anlayış yardımıyla, GQN nesneleri kontrol edebilir ve sahneyi hareket ettirirken, hataları kanıtladıklarında tahminlerini ayarlayarak kendini düzeltebilir.
GQN'de herhangi bir nesne sınırlaması bulunmuyor, ancak testler basit nesnelerle gerçekleştirildiğinden ötürü, karmaşık yapılar için bir şey söylemek henüz mümkün değil.

